SkeletonVis: Interactive Visualization for Understanding Adversarial Attacks on Human Action Recognition Models






 Chau.webp)
Demo Video
Abstract
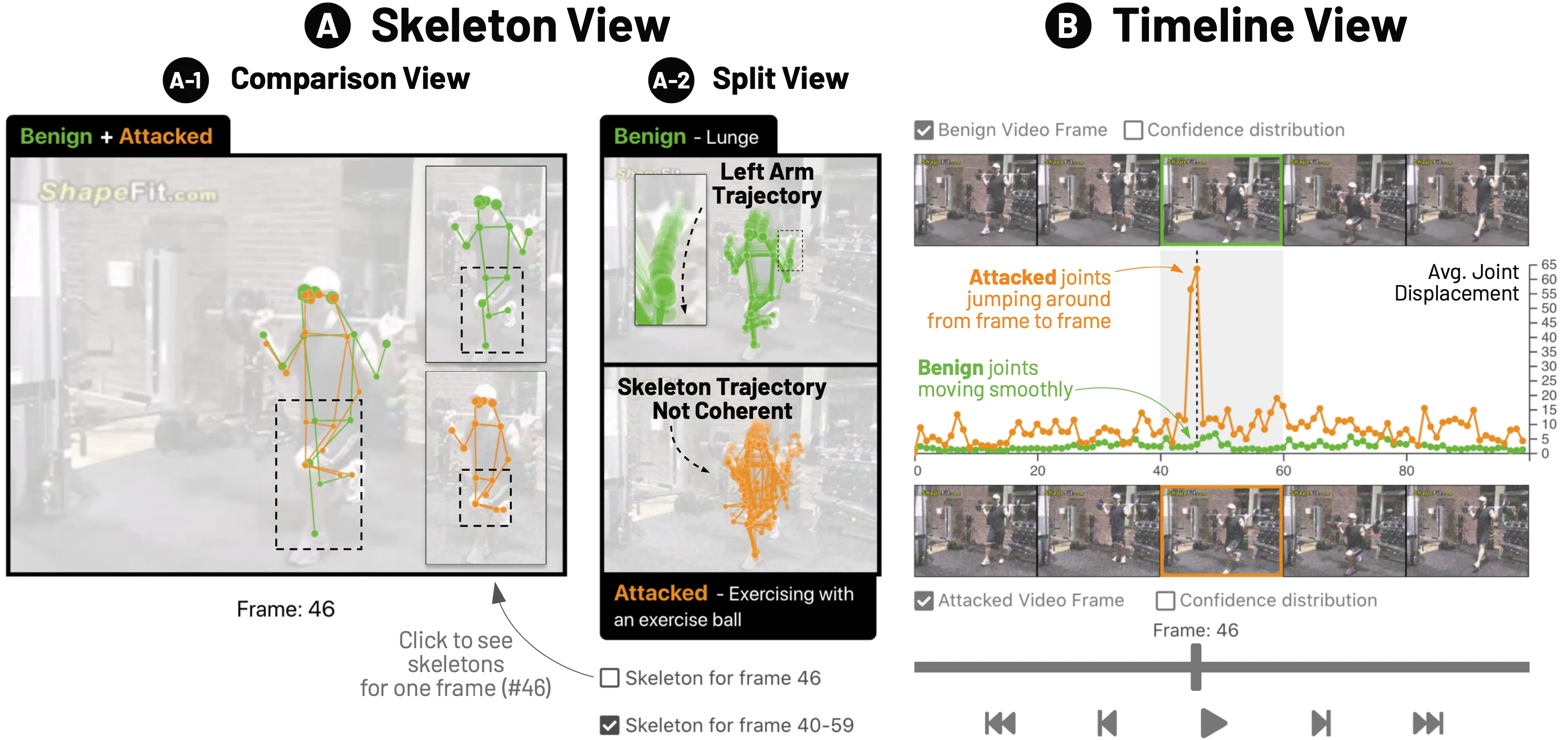
Skeleton-based human action recognition technologies are increasingly used in video based applications, such as home robotics, healthcare on aging population, and surveillance. However, such models are vulnerable to adversarial attacks, raising serious concerns for their use in safety-critical applications. To develop an effective defense against attacks, it is essential to understand how such attacks mislead the pose detection models into making incorrect predictions. We present SkeletonVis, the first interactive system that visualizes how the attacks work on the models to enhance human understanding of attacks.
Citation
SkeletonVis: Interactive Visualization for Understanding Adversarial Attacks on Human Action Recognition Models
@article{park2021skeletonvis,
title={SkeletonVis: Interactive Visualization for Understanding Adversarial Attacks on Human Action Recognition Models},
author={Park, Haekyu and Wang, Zijie J. and Das, Nilaksh and Paul, Anindya S. and Perumalla, Pruthvi and Zhou, Zhiyan and Chau, Duen Horng},
booktitle={AAAI, Demo},
year={2021}
}