UnMask: Adversarial Detection and Defense Through Robust Feature Alignment



 Chau.webp)
Abstract
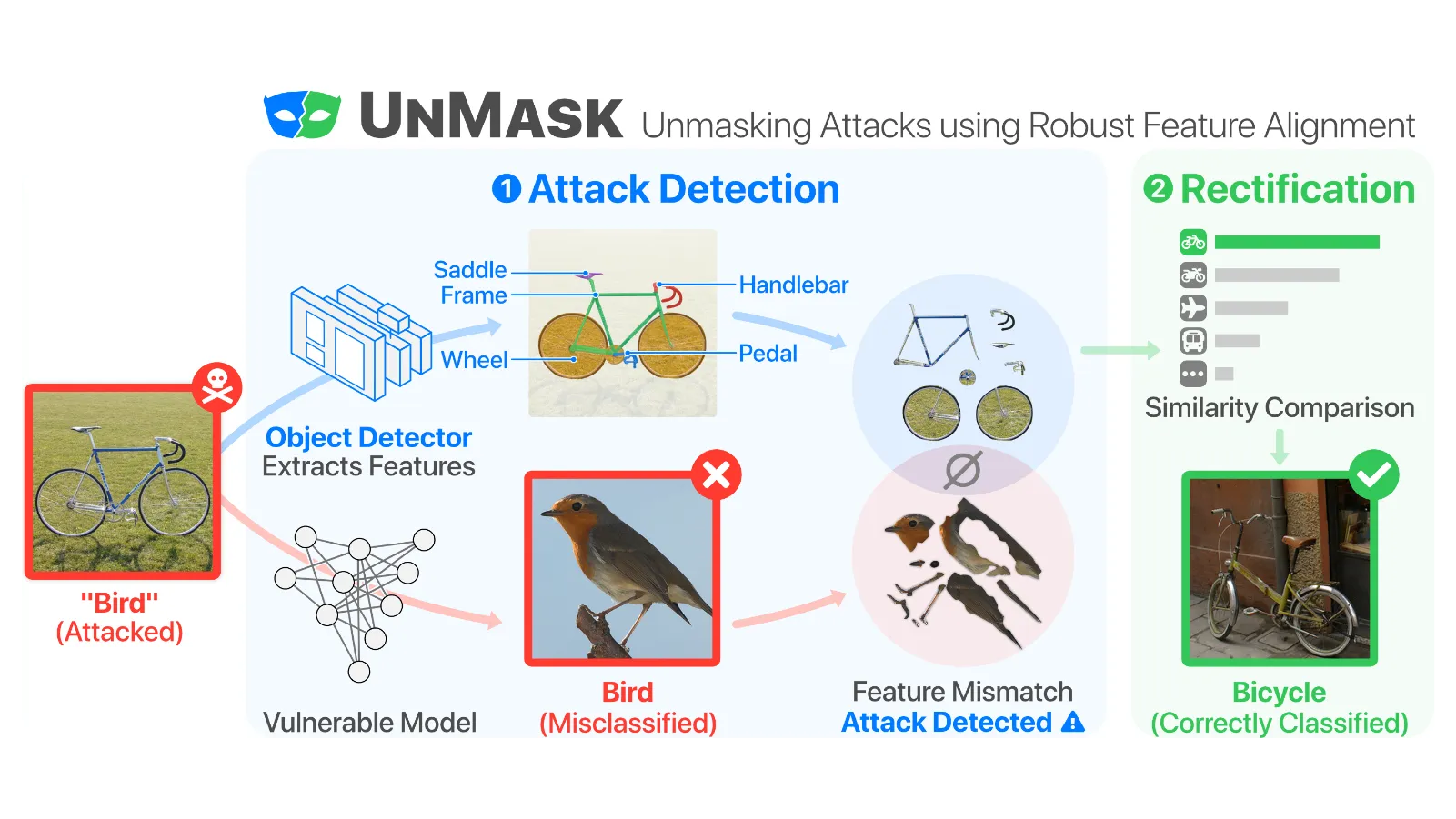
Deep learning models are being integrated into a wide range of high-impact, security-critical systems, from self-driving cars to medical diagnosis. However, recent research has demonstrated that many of these deep learning architectures are vulnerable to adversarial attacks--highlighting the vital need for defensive techniques to detect and mitigate these attacks before they occur. To combat these adversarial attacks, we developed UnMask, an adversarial detection and defense framework based on robust feature alignment. The core idea behind UnMask is to protect these models by verifying that an image's predicted class ("bird") contains the expected robust features (e.g., beak, wings, eyes). For example, if an image is classified as "bird", but the extracted features are wheel, saddle and frame, the model may be under attack. UnMask detects such attacks and defends the model by rectifying the misclassification, re-classifying the image based on its robust features. Our extensive evaluation shows that UnMask (1) detects up to 96.75% of attacks, with a false positive rate of 9.66% and (2) defends the model by correctly classifying up to 93% of adversarial images produced by the current strongest attack, Projected Gradient Descent, in the gray-box setting. UnMask provides significantly better protection than adversarial training across 8 attack vectors, averaging 31.18% higher accuracy. Our proposed method is architecture agnostic and fast. We open source the code repository and data with this paper: https://github.com/safreita1/unmask.
Citation
UnMask: Adversarial Detection and Defense Through Robust Feature Alignment
@article{freitasUnMaskAdversarialDetection2020,
title = {{{UnMask}}: {{Adversarial Detection}} and {{Defense Through Robust Feature Alignment}}},
shorttitle = {{{UnMask}}},
author = {Freitas, Scott and Chen, Shang-Tse and Wang, Zijie J. and Chau, Duen Horng},
year = {2020},
archivePrefix = {arXiv},
eprint = {2002.09576},
eprinttype = {arxiv},
journal = {arXiv:2002.09576}
}