VisCUIT: Visual Auditor for Bias in CNN Image Classifier



 Chau.webp)
Demo Video
Abstract
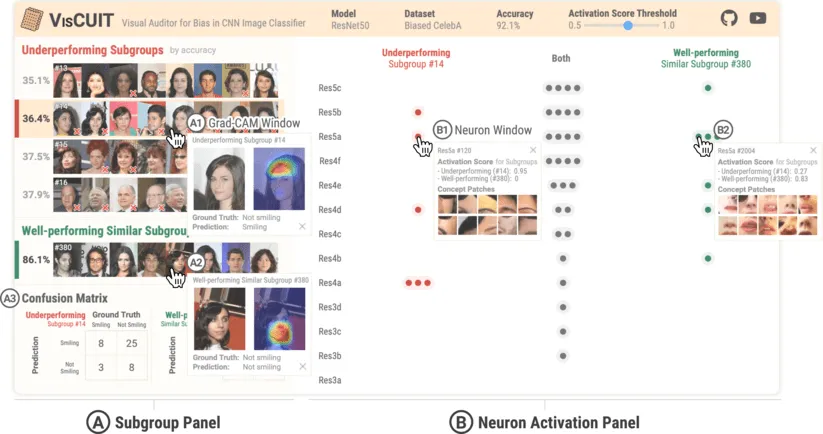
CNN image classifiers are widely used, thanks to their efficiency and accuracy. However, they can suffer from biases that impede their practical applications. Most existing bias investigation techniques are either inapplicable to general image classification tasks or require significant user efforts in perusing all data subgroups to manually specify which data attributes to inspect. We present VisCUIT, an interactive visualization system that reveals how and why a CNN classifier is biased. VisCUIT visually summarizes the subgroups on which the classifier underperforms and helps users discover and characterize the cause of the underperformances by revealing image concepts responsible for activating neurons that contribute to misclassifications. VisCUIT runs in modern browsers and is open-source, allowing people to easily access and extend the tool to other model architectures and datasets. VisCUIT is available at the following public demo link: https://poloclub.github.io/VisCUIT. A video demo is available at https://youtu.be/eNDbSyM4R_4.
Citation
VisCUIT: Visual Auditor for Bias in CNN Image Classifier
@inproceedings{leeVisCUITVisualAuditor2022a,
title = {{{VisCUIT}}: {{Visual}} Auditor for Bias in {{CNN}} Image Classifier},
booktitle = {Proceedings of the {{IEEE}}/{{CVF}} Conference on Computer Vision and Pattern Recognition ({{CVPR}})},
author = {Lee, Seongmin and Wang, Zijie J. and Hoffman, Judy and Chau, Duen Horng (Polo)},
year = {2022},
month = jun
}